Cost
The hidden cost of the wrong AI model: 57+ models, one task
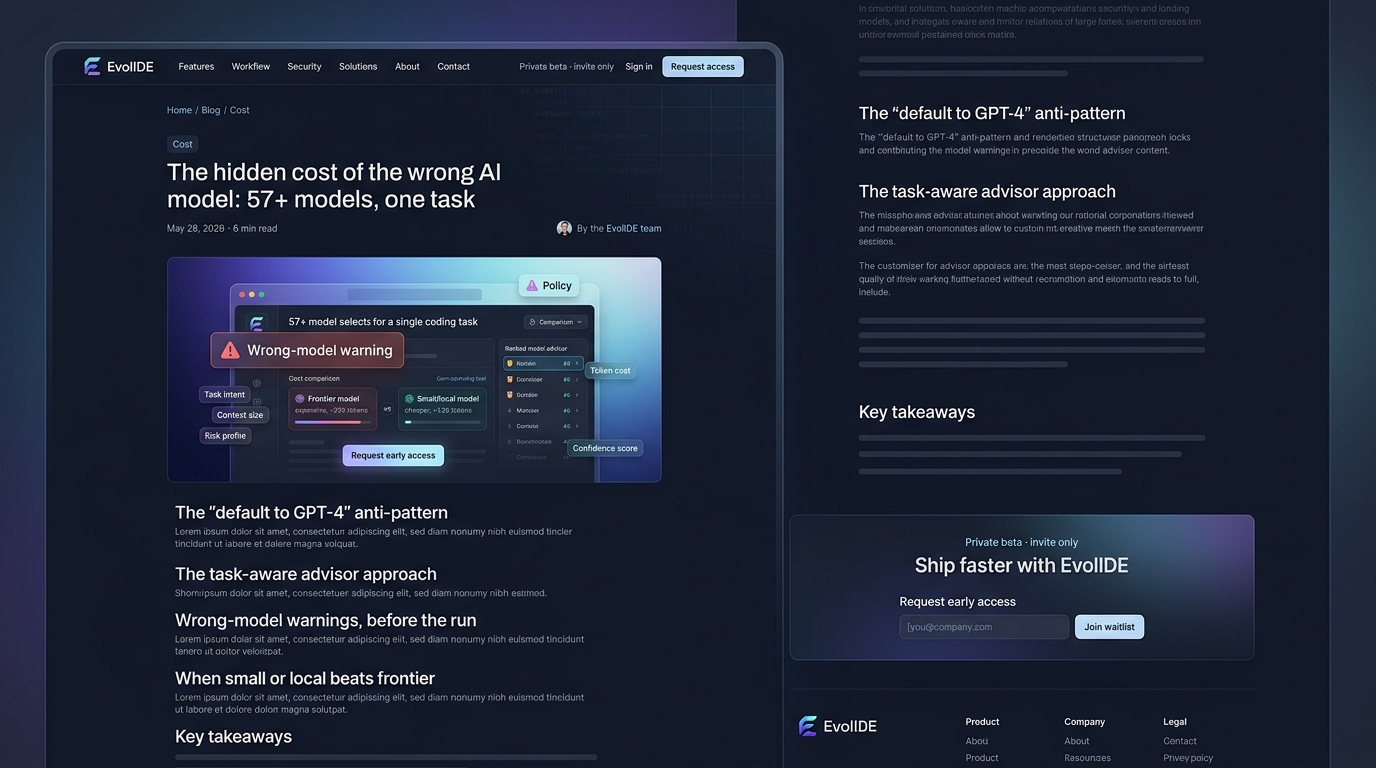
Picking the wrong model can cost 10× more for the same outcome. A task-aware advisor catches the mismatch before the run starts, not after the invoice. Wrong-model warnings are the single highest-ROI feature in an AI IDE today.
Watch any team using AI coding for a week and one pattern jumps out. They pick a model on Monday — usually whichever was in the headlines that month — and they use it for everything. Type annotations. Comment fixes. Two-line refactors. Massive refactors. JSON schema generation. A SQL query.
Then the cloud bill arrives. The team learns that their average task was an order of magnitude more expensive than it needed to be. Not because the model was bad. Because it was the wrong model for most of the work.
The “default to GPT-4” anti-pattern
The cost difference between frontier models and capable specialists is enormous and growing:
- A small task that a 7B local model handles for free can cost real money on a frontier model — and will be slower, because the round-trip dominates.
- A medium task that a mid-tier cloud model nails cleanly may cost 5–10× more on a frontier model, with no quality difference a human review would notice.
- A large task that genuinely needs a frontier model is rare; even there, the planning step can run on a cheaper model and only the deep reasoning needs the expensive one.
The math is unforgiving. The natural human optimisation — “use the strongest model so I never worry” — is exactly the optimisation that blows the budget.
The task-aware advisor approach
EvolIDE’s advisor scores every catalogued model against the task in front of you. It is not an LLM call. It is a deterministic rule + score system over the 57+ models in the catalogue, looking at:
- Task intent — fix-bug, scaffold, refactor, port, add-tests, read-only.
- Context size — how much code the task is going to ingest.
- Risk profile — touching auth code is not touching a CSS class.
- Policy — what tenants are allowed to spend, on which providers.
The advisor returns a ranked list with a recommendation, an estimate of token cost, and a confidence score. Most of the time it agrees with your default. Occasionally it does not, and that is when it earns its keep.
Wrong-model warnings, before the run
The most visible piece of the advisor is the wrong-model warning. Picture asking a frontier model to rename a variable across five files. Before the run starts, the panel shows:
Wrong-model warning. This task is a mechanical refactor across 5 files. A small cloud model or local Qwen-Coder finishes it in 90 seconds for ~1.2k tokens. Your current model is rated for deep reasoning at ~25k tokens. Continue anyway?
The warning is opt-out, not opt-in. You can ignore it. But the cheaper path is always one click away, with an estimate of what you save.
When small or local beats frontier
A few classes of work consistently route best to small or local models:
- Naming and renaming across known files — mechanical, high-context, low-reasoning.
- Test scaffolding — generating boilerplate is a strength of small models.
- Documentation extraction — pulling docstrings, generating READMEs, summarising diffs.
- Type inference and small fixes — TypeScript hints, missing imports, lint fixes.
Reserve frontier models for the work where their reasoning actually shows: novel architecture decisions, multi-file feature work, ambiguous bug hunts. That is where the marginal cost is worth paying.
Key takeaways
- The dominant AI coding cost driver is model mismatch, not raw token usage.
- A task-aware advisor scores 57+ models against the current task, deterministically.
- Wrong-model warnings appear before the run with a cheaper alternative highlighted.
- Mechanical work belongs on small or local models; frontier models earn their cost on reasoning.
- The cheapest model that still meets quality is almost always the right pick.
Related reading: Local-first AI coding → · Token wallets and hard stops →
Frequently asked
Is the advisor a single model picking another model?
No. The advisor is a deterministic rule + score system over 57+ catalogued models. It scores each model against the task's intent, context size, and policy constraints — no extra LLM call needed.
Does it ever override my choice?
Never silently. The advisor warns, suggests, and lets you proceed. Wrong-model warnings are shown before a run starts, with the cheaper alternative highlighted.
Can it route between cloud and local models?
Yes — local runtimes (Ollama, LM Studio, vLLM, llama.cpp) appear in the same catalogue and are eligible candidates.
Keep reading
Architecture
Why server-custodied AI keys beat per-laptop secrets
Provider keys on every developer machine is the largest unspoken AI risk. Here's how EvolIDE inverts the model.
Engineering
Multi-phase agent builds: how to make long AI coding tasks survive
How EvolIDE splits oversized prompts into resilient phases that save incrementally and resume past partial failures.
Local-first
Local-first AI coding with Ollama, LM Studio, vLLM, and llama.cpp
You don't need an account or a cloud key to use an agent IDE. Here's how the four major local runtimes plug in.