Operations
Token wallets and hard stops: spending guardrails for AI coding teams
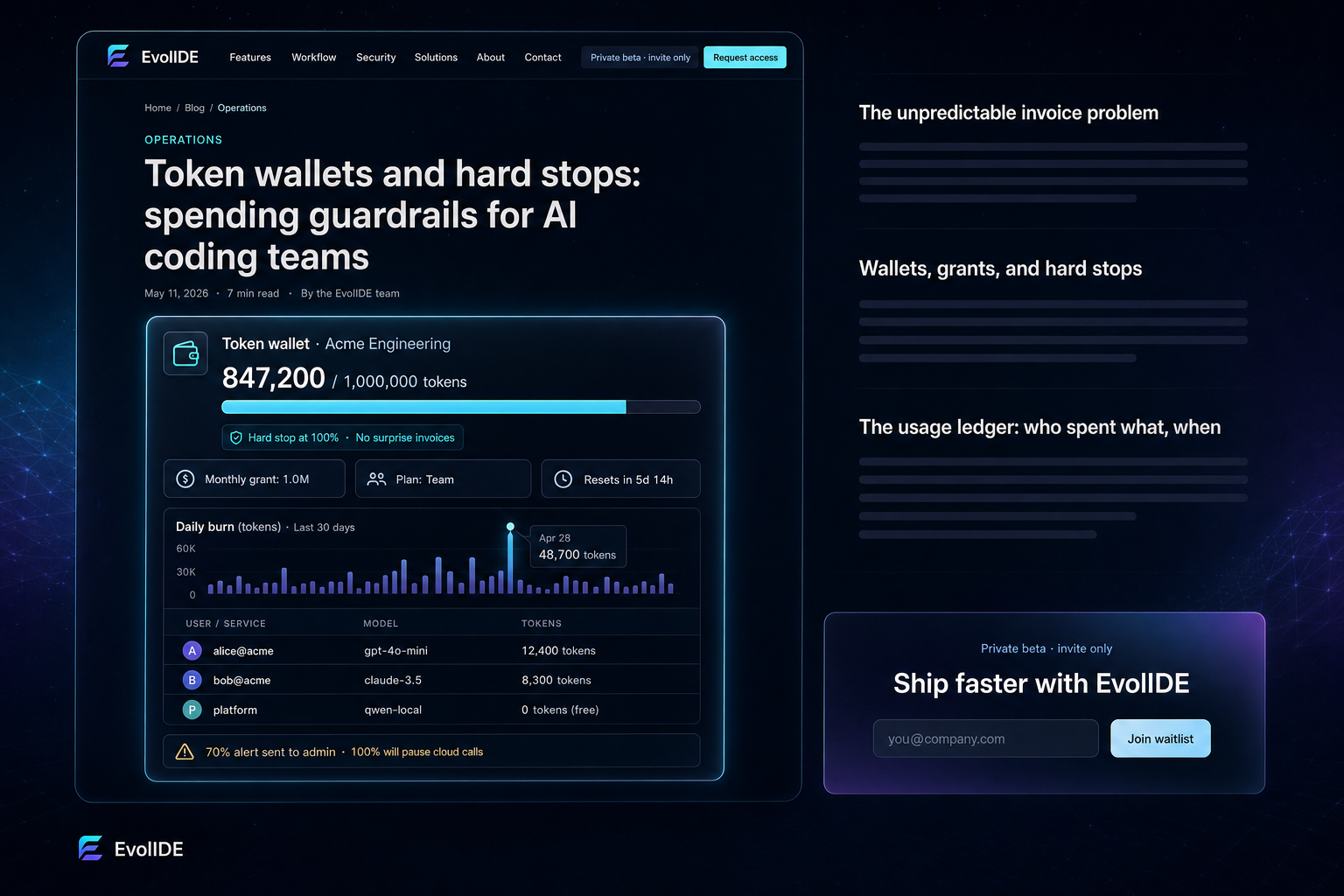
Unbounded AI coding spend is a runaway risk for engineering org rollouts. Per-tenant token wallets, monthly grants, and hard stops turn “how much did we spend?” from a post-hoc question into a real-time signal — with audit-grade granularity.
AI coding spend has a peculiar shape. It is invisible until the invoice lands. There is no warning light at 80% of budget. There is no per-developer cap that a security team can enforce without trusting the client. There is rarely a clean answer to “which team burned the most last month?”
Engineering finance starts to care about this around the time a pilot graduates to general availability. Suddenly the question is not “is AI coding worth $50 a head” — it is “is there a $50k surprise waiting for us this quarter?”
The unpredictable invoice problem
Three properties of frontier-model billing make spend hard to predict:
- Token usage is super-linear in task complexity — a slightly harder task can burn 4× the tokens of an easy one.
- Re-runs compound — when the first attempt fails, the second uses the failed context, so spend grows faster than success rate improves.
- Spend is opaque to the user — a developer running a model has very little intuition for what the next prompt will cost.
Capping at the provider is a blunt instrument: once the cap hits, everyone is locked out at once, regardless of which team caused the burn. You need a finer-grained mechanism.
Wallets, grants, and hard stops
EvolIDE’s metering layer wraps every cloud call in a wallet abstraction. Each tenant has:
- A monthly grant attached to their plan, replenished on schedule. Earned credits (referrals, onboarding milestones) accrue on top.
- A paid balance for top-ups beyond the grant — billed predictably, never with a surprise.
- A hard stop at zero. When the balance is exhausted, the gateway refuses cloud calls with a clear
insufficient_tokensresponse. Local-model calls keep working.
The hard stop happens server-side. There is no client-side flag the user can toggle off to keep spending. The wallet is the source of truth.
The usage ledger: who spent what, when
Every metered call writes a ledger entry: tenant, user, model, tokens in, tokens out, cost, revenue bucket, timestamp. The ledger is queryable per tenant, per user, per model, per day. The admin dashboard surfaces three views by default:
- Spend by tenant — for executive reporting and budgeting.
- Spend by user — for spotting outliers and onboarding gaps.
- Spend by model — for FinOps-style optimisation (this is where wrong-model warnings pay off).
The ledger doubles as an audit log. Every cloud call is reconstructable end-to-end without re-running anything.
Designing budgets that don’t slow teams down
The hardest part of token budgets is the social side. A budget that is too tight feels punitive and pushes teams to bypass the tool. A budget that is too loose stops being a budget. A few patterns we recommend:
- Set the cap at 2–3× expected median monthly spend. Generous enough that nobody hits it unless something is genuinely off; tight enough that an incident is visible.
- Alert at 70% before stop at 100%. Hard stops are emergency brakes; soft alerts are conversations.
- Default to local for mechanical tasks. The advisor will route there automatically if you let it. Local doesn’t debit the wallet at all.
- Separate platform spend from team spend. If platform agents (background runs, smoke loops) ride on the same wallet as developer interactions, the platform always eats the budget.
Key takeaways
- AI coding spend is super-linear and opaque without explicit budgets.
- Per-tenant wallets, plan grants, and hard stops bound the worst case at the gateway.
- A queryable usage ledger turns audit and FinOps into a normal report, not an exercise.
- Hard stops are emergency brakes; pair them with 70% soft alerts.
- Route mechanical work to local to keep the cloud wallet for work that earns it.
Related reading: The hidden cost of the wrong model → · Server-custodied keys →
Frequently asked
What happens when a tenant hits the hard stop?
Cloud calls are refused with a clear `insufficient_tokens` response. Local-model runs continue uninterrupted. Admins see a wallet-exhausted event in the dashboard.
Can grants be auto-replenished?
Yes — plans carry a monthly token grant that resets on schedule. Earned credits (e.g. from referrals or onboarding milestones) accrue on top.
Does every call hit the wallet?
Only metered cloud calls draw from the wallet. Local-model runs, brain decisions, and free-tier features are tracked but do not debit.
Keep reading
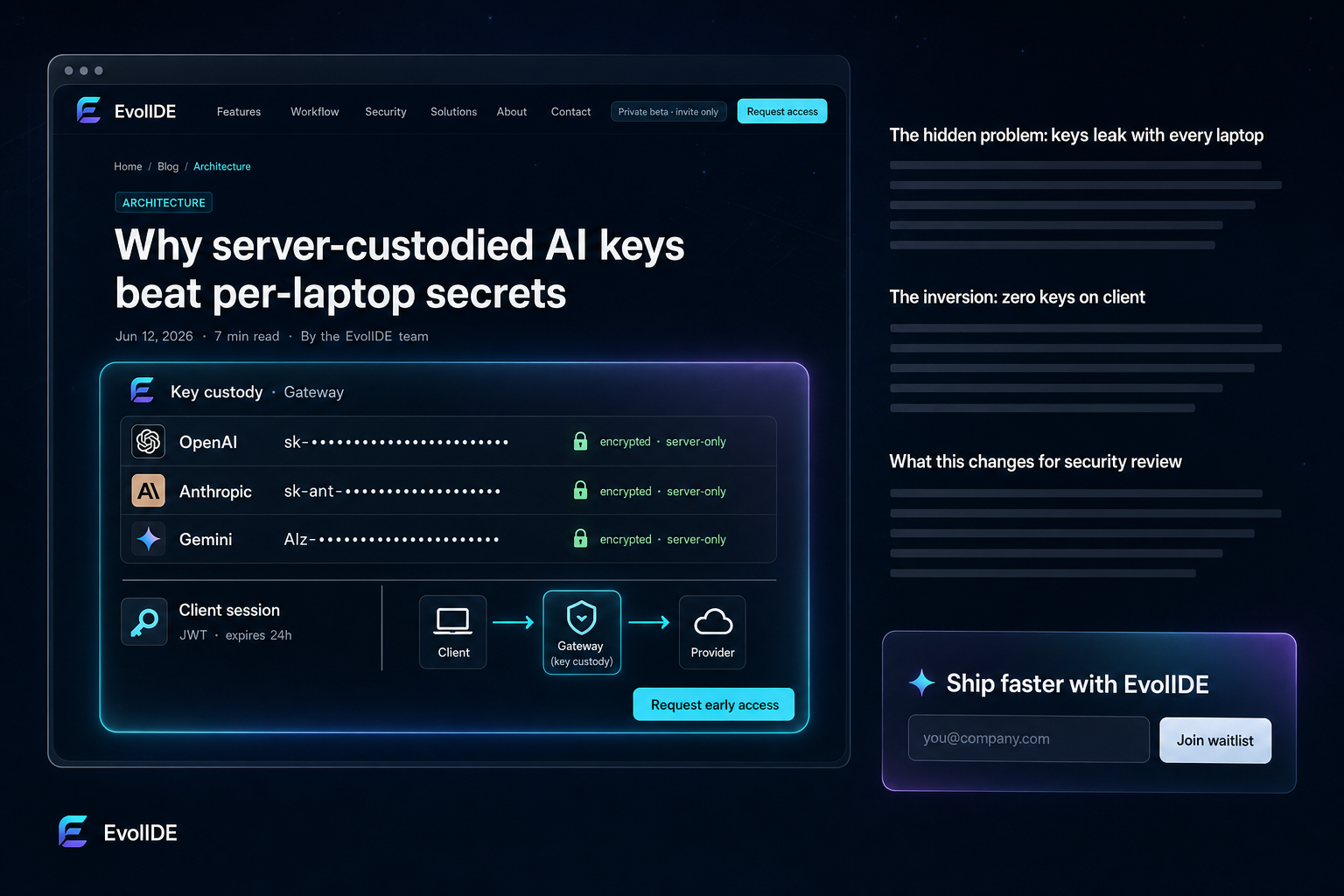
Architecture
Why server-custodied AI keys beat per-laptop secrets
Provider keys on every developer machine is the largest unspoken AI risk. Here's how EvolIDE inverts the model.
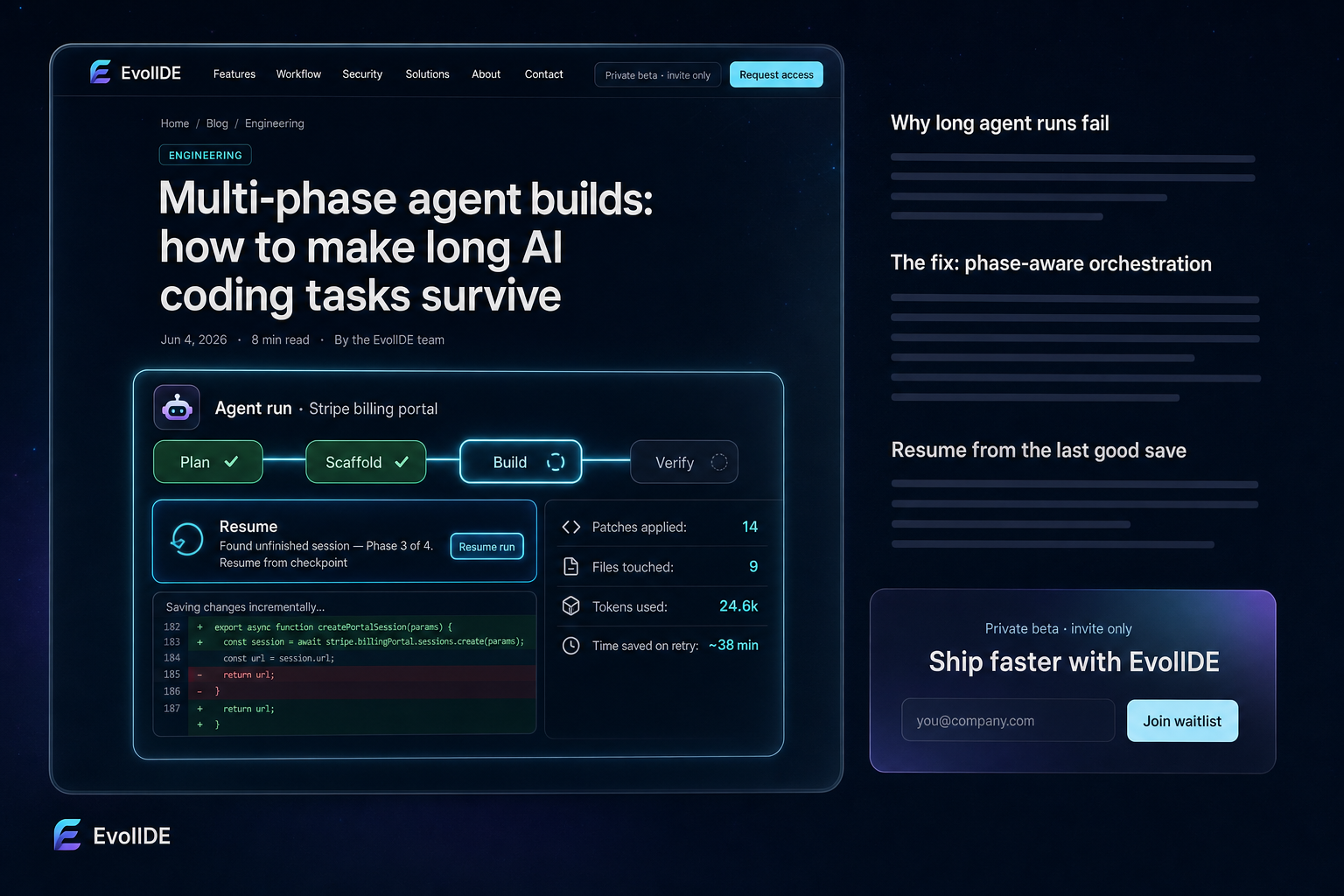
Engineering
Multi-phase agent builds: how to make long AI coding tasks survive
How EvolIDE splits oversized prompts into resilient phases that save incrementally and resume past partial failures.
Cost
The hidden cost of the wrong AI model: 57+ models, one task
Picking the right model is often the difference between $1 and $10 for the same outcome. The advisor explains why.