Delivery
Background agents with isolated git worktrees: an enterprise delivery cockpit
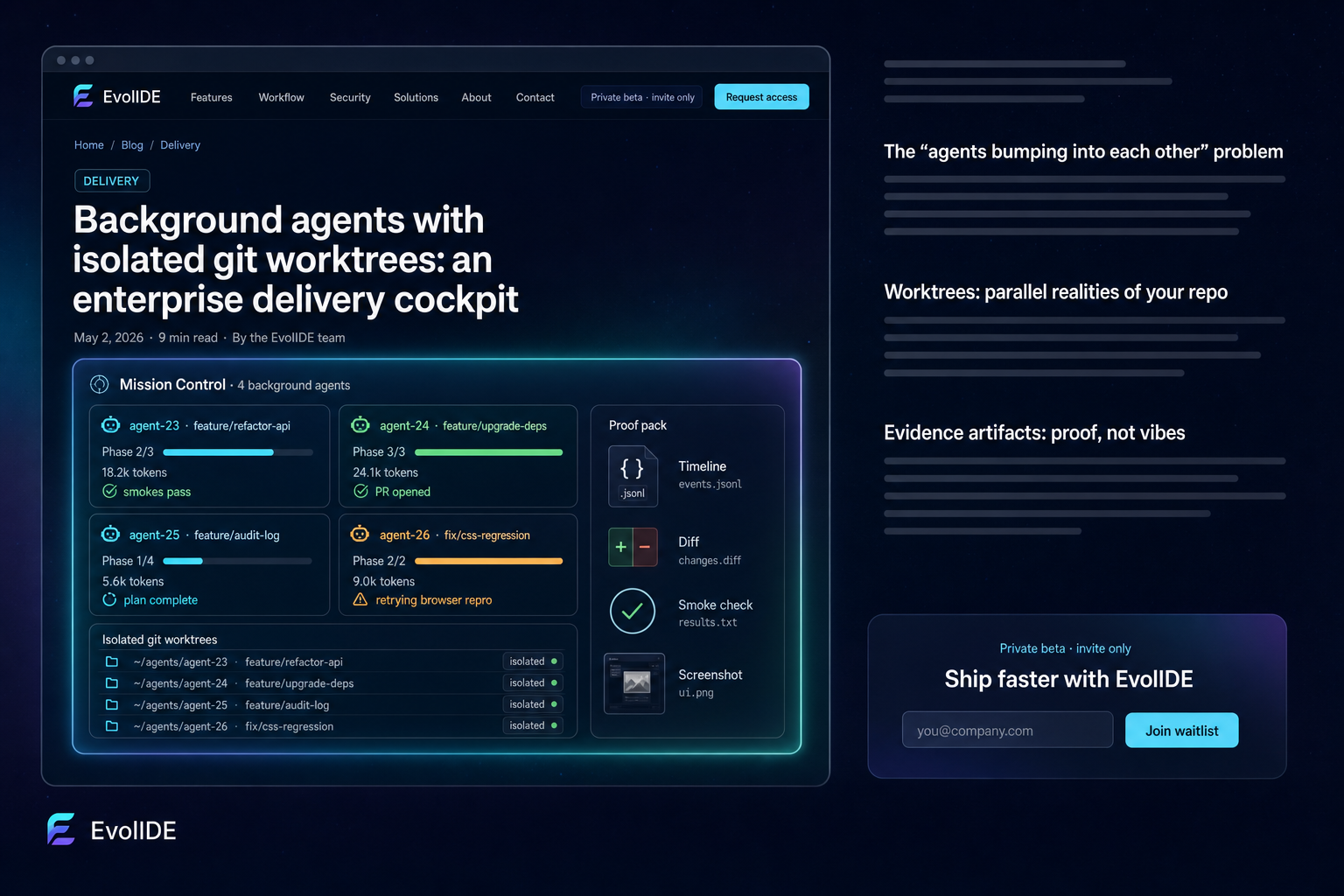
Running ten AI agents in parallel against the same repo is a recipe for stomped commits and tangled diffs — unless each agent gets its own isolated git worktree, an evidence trail, and a clean rollback path. Worktrees are the unsung hero of an enterprise AI delivery cockpit.
Foreground agents — the kind that edit files while you watch — are the easy case. They take turns, they touch one workspace at a time, you review every patch as it lands. The complications only start when you want to run agents in the background: overnight, in parallel, on multiple tasks at once. That is where most AI IDEs quietly fall apart, and where the workspace design starts to matter more than the model.
The “agents bumping into each other” problem
Three failure modes show up the moment you let agents run in parallel against a shared checkout:
- Stomped working tree — agent A is mid-edit when agent B switches branches. Half-applied changes from both runs end up in the working directory.
- Conflicting branches — both agents try to commit to the same feature branch, or one creates a branch the other was about to.
- Indeterminate state — when something goes wrong, “what did agent A actually change?” is unanswerable because B has been editing the same files.
The right primitive to fix this is not new — it has been sitting in git for over a decade. Worktrees.
Worktrees: parallel realities of your repo
A git worktree is an independent working directory attached to the same underlying repository. Multiple worktrees share the .git object database, so creating one is cheap (no re-fetch, no duplicated history) but each lives in its own folder on disk with its own HEAD, branch, and working tree.
# repo lives at ~/proj
git -C ~/proj worktree add ~/agents/agent-23 feature/refactor-api
git -C ~/proj worktree add ~/agents/agent-24 feature/upgrade-depsEach agent gets its own folder. They can both run, both commit, both push, without ever touching each other’s files. When an agent finishes, EvolIDE removes the worktree; if a teammate wants to inspect the run before merge, the worktree lives until cleanup.
On systems without git (rare for serious repos) EvolIDE falls back to a shallow copy of the relevant working set. The agent contract is the same: a folder I own, alone.
Evidence artifacts: proof, not vibes
An isolated workspace is necessary but not sufficient. The other half is evidence — a per-agent record of what happened that a reviewer can read in two minutes, not two hours. EvolIDE attaches a proof pack to every background run:
- Timeline — a JSONL stream of every step the agent took, with timestamps.
- Patch diffs — the actual changes applied, separately from the commit.
- Smoke results — pass/fail for every check the agent ran on its own changes.
- Model calls — which model, how many tokens, how much it cost.
- Acceptance score — an aggregate of the above, surfaced on the PR description.
Reviewers do not have to trust the agent. They have to look at the proof pack and decide whether to trust this particular run. That is a much easier judgement.
Browser-to-code: closing the loop
Worktrees and proof packs cover the inbound side — what the agent did to the code. The outbound side is just as important: what the code did when it ran. The browser-to-code feedback loop closes this. An agent that wrote a UI change can spin up a headless browser, exercise the change, capture any errors, and feed them back as the next iteration’s prompt — all inside its own worktree.
The same primitive works for visual regressions: a screenshot diff against the baseline becomes evidence the agent attaches to the proof pack. “Pixel-perfect” is no longer something a human has to babysit; it is part of the agent’s own success signal.
The cockpit
Mission Control sits above all of this — a single dashboard showing every background agent, their phase, their token spend, the worktree on disk, and the merge state of their PR. From there you can pause a run, retry a phase, or terminate the whole thing. The agents do the work; the cockpit makes the work legible.
Key takeaways
- Parallel agents on a shared checkout collide; isolated worktrees fix it cleanly.
- Git worktrees are cheap, share object history, and give each agent its own working tree.
- Evidence packs (timeline + diffs + smoke + model calls) make agent runs reviewable in minutes.
- Browser-to-code loops close the inbound/outbound gap with screenshot and error feedback.
- Mission Control is the cockpit that makes parallel agent work legible at scale.
Related reading: Multi-phase agent builds → · EvolIDE for delivery teams →
Frequently asked
Why worktrees instead of separate clones?
Worktrees share the same .git directory while keeping working trees independent — cheaper, faster, and they preserve a shared object database for cross-agent context.
What evidence does an agent produce?
A timeline (JSONL), patch diffs, smoke results, model calls and their token cost, plus a final proof pack attached to the PR description.
Can I review a background run before it merges?
Yes — every background run opens a PR with the proof pack attached. Nothing auto-merges unless the merge gate is explicitly green and policy allows it.
Keep reading
Architecture
Why server-custodied AI keys beat per-laptop secrets
Provider keys on every developer machine is the largest unspoken AI risk. Here's how EvolIDE inverts the model.
Engineering
Multi-phase agent builds: how to make long AI coding tasks survive
How EvolIDE splits oversized prompts into resilient phases that save incrementally and resume past partial failures.
Cost
The hidden cost of the wrong AI model: 57+ models, one task
Picking the right model is often the difference between $1 and $10 for the same outcome. The advisor explains why.